
Solving the game “Overcooked” with Reinforcement Learning
I wanted to see whether a hand-rolled PPO agent could solve a messy multi-agent kitchen environment. It did, but only after repeated collapse/recovery cycles and a lot of practical debugging. Overcooked is a cooperative cooking game where two agents must coordinate movement and tasks to prepare and deliver soups under time pressure.
Key Takeaways
- PPO can solve this setup, but stability depends heavily on implementation details.
- KL monitoring and reward shaping made the difference between collapse and progress.
- Multi-agent behavior can converge to surprising but valid local strategies.
When I was a kid, I was convinced that game AIs were genuinely learning. Later, of course, I realised they were mostly clever scripts. Still, the idea of a system that actually learns while playing a game (or solving an environment), stuck with me. I found an Overcooked Gym Environment where the job is to cook onion soup - three onions, twenty seconds of simmering, and no cheese on top (I am not sure it would be a good soup). It’s a wonderful co-op game on Switch, and it makes for a surprisingly fun RL playground.
It felt like the perfect chance to experiment with reinforcement learning from scratch, and my mind went immediately to PPO. I’d read the paper years ago and loved how deceptively simple the whole idea felt. Can we teach a model (also called an agent) to solve this environment, which means in this case to successfully deliver soups?
With the state space being fairly high-dimensional, classic Q-learning isn’t really an option. So you let a multilayer perceptron approximate the value function as a function of the current state. This approximator is called the “critic” because it evaluates the current state the agent is in. Then the “actor,” guided by that critic and the current state, picks the next action. That elegance pulled me right in.
So I implemented PPO in PyTorch, and after an unreasonable amount of tuning - hyperparameters, reward shaping, bug fixing and more hyperparameters - it finally started behaving:

Emergent multi-agent behavior in early successful runs.
Well… “behaving.” It’s multi-agent, and one of the agents decided its optimal policy was simply to avoid the other player entirely, haha. Honestly, I found that hilarious enough to write this post. Along the way I gained new appreciation for people who work in RL full-time. Even in this small environment, I ran into outright model collapse, multiple times in a row.
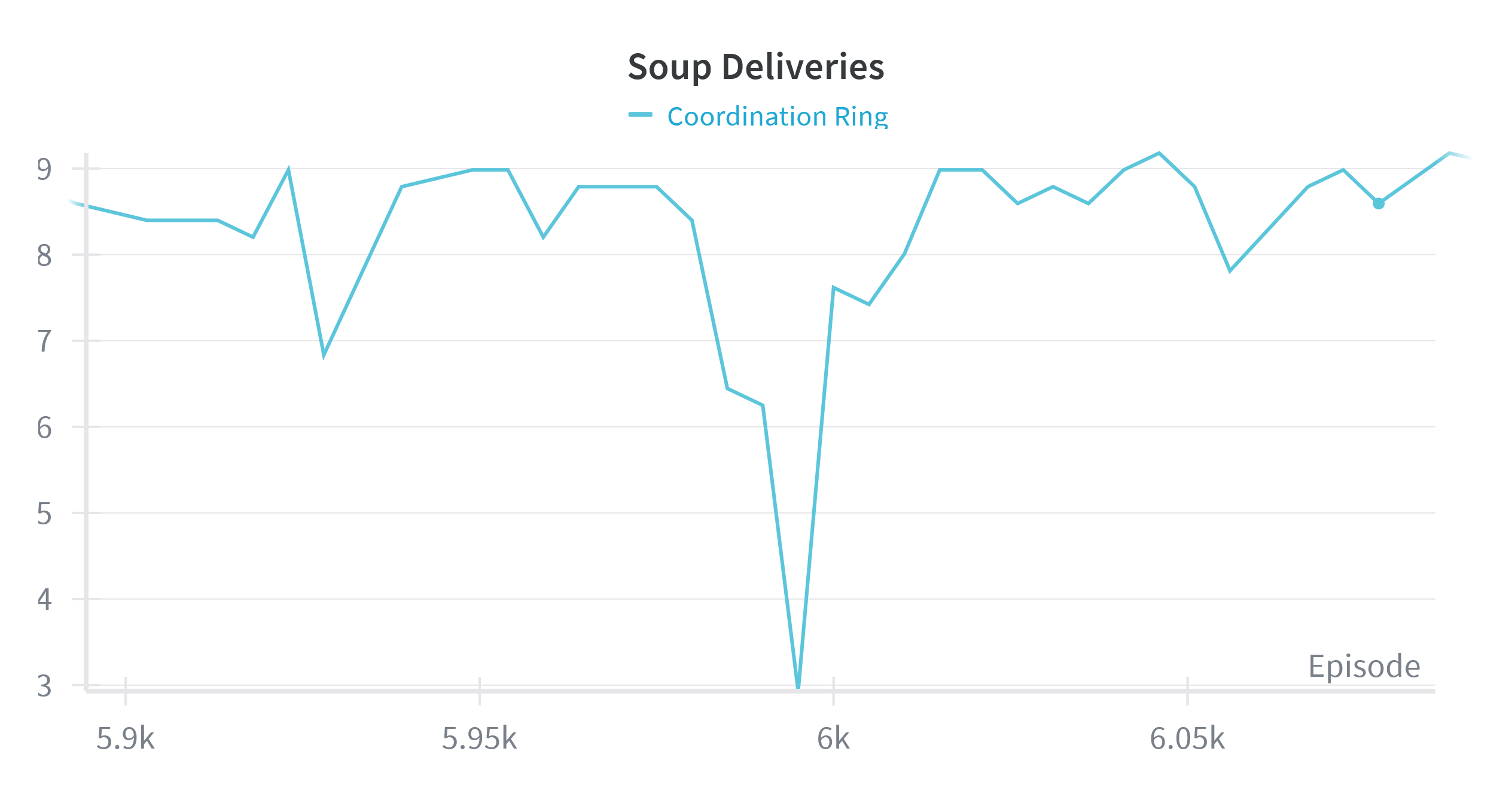
Training instability: repeated collapse and recovery phases.
I’d have loved to dig deeper into what was going on there, if it’s common, if it can be avoided, but this was just a weekend project. And technically, the system did learn something and solve the environment, so it’s a success.
One surprise: the implementation details from this blog were spot-on; my “breakout” moment - when the model finally figured out the task - really did happen at around 400 episodes. How can this be so accurate and general? And before I fixed my last bug, my estimated KL divergence was indeed above 0.02, just as warned.
I can fully recommend everyone to try this out and experience this moment too; you don’t have to implement PPO yourself, you can use TorchRL. The amount of tinkering you will have to do will be still extreme. The moment when you see that soups are actually being delivered is incredible!!