
Visualizing Whisper: Mapping Cross-Attention to Time
I wanted better token timestamps without introducing a separate forced-alignment model. Inspecting Whisper’s decoder cross-attention gave a surprisingly precise alignment signal directly from the model internals. Whisper uses an encoder-decoder architecture: the encoder compresses the audio into features, and the decoder generates text token by token from those features. Cross-attention is the decoder’s mechanism for choosing which encoder time regions to focus on for each generated token.
Key Takeaways
- Cross-attention weights provide usable token-to-time alignment.
- Alignment remained stable even with long inserted silence segments.
- This creates a practical internal diagnostic tool for Whisper pipelines.
I was curious if we could improve Whisper’s timestamps by peeking inside its “brain”-specifically, by looking at its decoder cross-attention weights. It turns out, we can.
The Concept: Where is the Model ‘Listening’?
Whisper is an encoder-decoder Transformer. While the encoder processes the entire audio chunk, the decoder generates text token by token. For every token it creates, it must “look back” at the encoder’s output to find the relevant audio features. This “look back” is captured in the cross-attention matrices.
By extracting these matrices, we can see exactly which parts of the input spectrogram the model is focusing on for each specific token.
In the example below, I used audio containing two sentences: “Is there a McDonalds around here?” and “I’m here often.” You can see the generated tokens on the left (Y-axis) and watch how the model’s focus shifts across the encoder’s output (X-axis) as it decodes the audio into text.
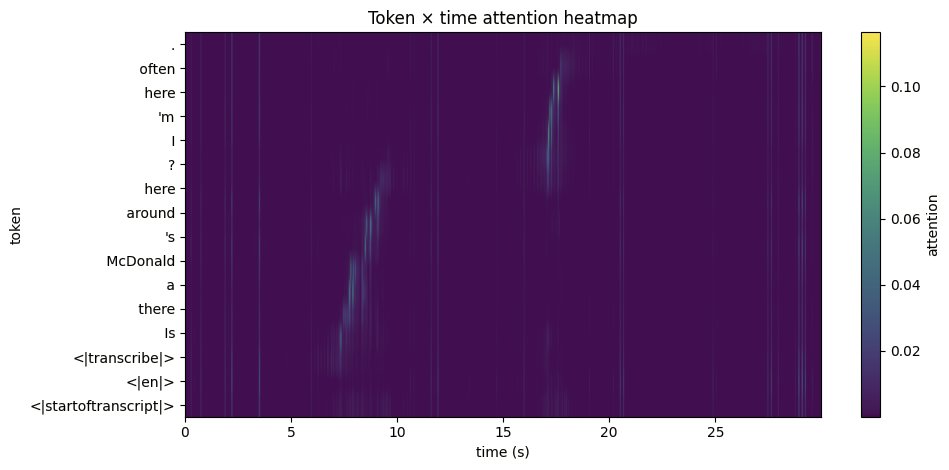
Token-to-time alignment heatmap with a 7-second pause.
Testing with Silence
To verify this, I tested the model with audio containing long, deliberate pauses (7 and 13 seconds) between sentences. As shown in the heatmaps, the attention shifts with surgical precision to match the actual timing of the speech.
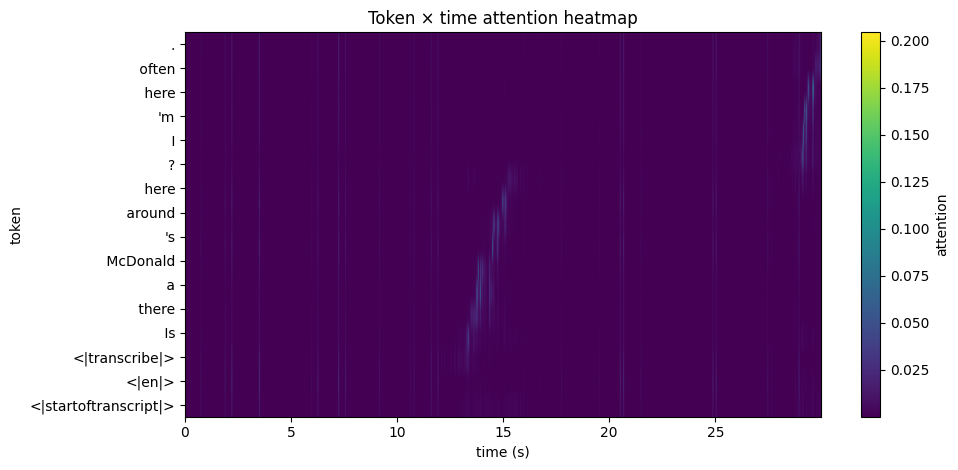
Token-to-time alignment heatmap with a 13-second pause.
In these visualizations:
- Y-axis: The generated tokens.
- X-axis: The audio timeline (spectrogram).
- Brightness: Strength of attention.
Why This Matters
What’s fascinating is that this alignment is emergent. We didn’t train the model to align tokens to time; it simply has to do this to be an effective transcriber.
Even with 1D convolutions and transpositions happening under the hood, the cross-attention patterns map linearly back onto the original audio. It’s a satisfying reminder that the most efficient way for the model to solve the ASR task is also the most logical: it listens to the audio in chronological order, token by token.
This approach gives us a “free” alignment tool that doesn’t require external forced-alignment models (like Wav2Vec2 or Montreal Forced Aligner), making it a powerful internal diagnostic for any Whisper-based pipeline.
Final Thoughts
Seeing the internal weights align so neatly with the physical reality of the audio signal is one of those moments where the “black box” of deep learning feels a little more transparent. It confirms that the cross-attention mechanism isn’t just a mathematical convenience-it’s a direct map of the model’s focus in time.